

A transformação digital exige velocidade, e no universo de infraestrutura, isso significa automação completa. Se existe uma linguagem que se tornou a ferramenta preferida do engenheiro de DevOps para integrar e coordenar serviços, essa linguagem é o Python.
No lugar de executar comandos repetitivos ou alternar entre múltiplas interfaces, o Python permite que você crie scripts que comandam toda a sua infraestrutura. Neste guia prático, você verá como usar o Python para DevOps para mergulhar na gestão programática do seu cluster. Aprenderemos a configurar, conectar e executar operações essenciais, como listar Pods e Services, consumindo a API do Kubernetes diretamente com a biblioteca oficial.
Por que Python para a Automação do Kubernetes?
A automação de ambientes complexos como o Kubernetes (K8s) não é apenas uma boa prática, é uma necessidade. Usar comandos kubectl repetidamente é ineficiente e propenso a erros.
A Vantagem da Linguagem e do Ecossistema
O Python oferece uma sintaxe limpa, tornando scripts complexos fáceis de ler e manter. Mas o verdadeiro trunfo é o módulo kubernetes-client, o SDK oficial mantido pela própria comunidade Kubernetes. Ele traduz toda a complexidade da API REST em classes e métodos intuitivos de Python, facilitando a vida de quem atua com Kubernetes no dia a dia.
Autenticação: O Arquivo kubeconfig
O grande benefício de usar o kubernetes-client é que ele herda automaticamente a configuração do seu ambiente kubectl. Ele procura e carrega as credenciais e o contexto ativo do seu arquivo padrão: ~/.kube/config. Isso torna a conexão inicial trivial.
Mãos à Obra: Preparando o Ambiente
Agora que entendemos o porquê, vamos configurar nosso ambiente de desenvolvimento. Trabalhar com ambientes virtuais é uma prática essencial no desenvolvimento Python, pois permite isolar as dependências de cada projeto, evitando conflitos entre bibliotecas e mantendo seu sistema organizado.
Criando o Ambiente Virtual
python3 -m venv .venv
Este comando cria um novo ambiente virtual na pasta .venv. O módulo venv do Python gera uma estrutura de diretórios isolada que conterá uma cópia do interpretador Python, o gerenciador de pacotes pip e todas as bibliotecas que você instalar posteriormente.
O nome .venv é uma convenção popular (o ponto inicial oculta a pasta em sistemas Unix/Linux), mas você pode escolher qualquer nome.
Ativando o Ambiente Virtual
source .venv/bin/activate
A ativação do ambiente virtual modifica temporariamente seu shell para usar o Python e pip isolados. Você notará que o prompt do terminal ganha um prefixo (.venv), indicando que o ambiente está ativo.
Observação importante: No Windows, o comando é diferente:
.venv\\Scripts\\activate
Atualizando o Pip
python3 -m pip install -U pip
Antes de instalar qualquer pacote, é boa prática atualizar o pip (Python Package Installer) para a versão mais recente. A flag -U (ou --upgrade) força a atualização. Isso garante acesso aos recursos mais recentes, correções de segurança e melhor compatibilidade com pacotes modernos.
Instalando as Dependências do Projeto
pip install kubernetes tabulate
Aqui instalamos duas bibliotecas essenciais: kubernetes, o cliente oficial Python para interagir com clusters Kubernetes, que permite gerenciar recursos como pods, deployments, services e outros objetos da API do Kubernetes programaticamente; e tabulate, uma biblioteca para formatação de dados em tabelas elegantes no terminal, ideal para exibir informações de forma organizada e legível.
Abrindo o Projeto no VS Code
code .
Este comando abre o Visual Studio Code na pasta atual (representada pelo .). O VS Code detectará automaticamente o ambiente virtual .venv e o configurará como interpretador padrão para o projeto.
Dicas Adicionais
Desativando o Ambiente Virtual
Quando terminar de trabalhar no projeto, execute:
deactivate
Salvando as Dependências
É recomendado criar um arquivo requirements.txt para documentar as dependências:
pip freeze > requirements.txt
Instalando em Outro Ambiente
Outros desenvolvedores podem recriar o mesmo ambiente com:
pip install -r requirements.txt
Ignorando o Ambiente Virtual no Git
Adicione .venv/ ao seu arquivo .gitignore para não versionar a pasta do ambiente virtual.
Listando Todos os Pods: O Exemplo Básico
Um dos primeiros passos na automação é obter o status dos recursos. O método list_pod_for_all_namespaces faz exatamente isso.
import re
from kubernetes import config
from kubernetes import client
from tabulate import tabulate
config.load_kube_config()
v1 = client.CoreV1Api()
result = []
pods = v1.list_pod_for_all_namespaces()
if pods:
for pod in pods.items:
namespace = pod.metadata.namespace
name = pod.metadata.name
status = pod.status.phase
row = [namespace, name, status]
result.append(row)
headers = ['Namespace', 'Nome', 'Status']
print('')
print(tabulate(result, headers=headers, tablefmt='simple'))
Entendendo o Código
Vamos quebrar o código em partes para entender cada etapa da automação:
Importações e Configuração Inicial
import re
from kubernetes import config
from kubernetes import client
from tabulate import tabulate
config.load_kube_config()
v1 = client.CoreV1Api()Primeiro, importamos os módulos necessários. O config.load_kube_config() é o ponto de partida: ele carrega automaticamente as credenciais do arquivo ~/.kube/config, usando o contexto ativo do seu kubectl. Em seguida, criamos uma instância de CoreV1Api(), que nos dá acesso aos recursos principais do Kubernetes, como Pods, Services e Namespaces.
Coletando Informações dos Pods
result = []
pods = v1.list_pod_for_all_namespaces()
if pods:
for pod in pods.items:
namespace = pod.metadata.namespace
name = pod.metadata.name
status = pod.status.phase
row = [namespace, name, status]
result.append(row)
O método list_pod_for_all_namespaces() consulta a API do Kubernetes e retorna todos os Pods de todos os namespaces do cluster. Iteramos sobre pods.items, extraindo três informações essenciais de cada Pod: o namespace onde ele está executando, o nome do Pod e seu status atual (Running, Pending, Failed, etc.). Cada linha é adicionada à lista result para formatação posterior.
Formatação e Exibição
headers = ['Namespace', 'Nome', 'Status']
print('')
print(tabulate(result, headers=headers, tablefmt='simple'))
Por fim, usamos a biblioteca tabulate para transformar nossa lista de dados em uma tabela formatada e legível. Os cabeçalhos definem o nome de cada coluna, e o formato simple cria uma tabela limpa e profissional no terminal.
Output
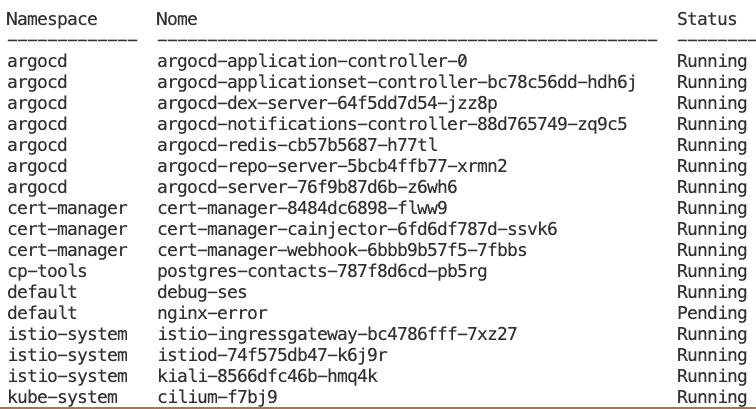
Boas Práticas de Automação DevOps com Python
A capacidade de consumir a API do Kubernetes abre infinitas possibilidades para a sua prática de DevOps:
Validação e Testes
Crie scripts Python para provisionar ambientes temporários (usando a API), executar testes de integração e, em seguida, destruir os recursos automaticamente.
Relatórios e Monitoramento
Use o Python para extrair métricas de status dos Pods, consumo de memória ou CPU (via API de Métricas) e gerar relatórios executivos.
Gestão de Recursos
Crie scripts que garantam que todos os Namespaces tenham ResourceQuotas definidos, aplicando governança de forma programática.
Conclusão
A união de Python para DevOps e a API do Kubernetes não é apenas uma tendência, mas o novo padrão para quem busca eficiência e controle total sobre a infraestrutura. Você tem em mãos uma ferramenta poderosa capaz de transformar tarefas manuais e repetitivas em processos rápidos, confiáveis e auditáveis.
Agora que você deu os primeiros passos, qual recurso complexo do Kubernetes você automatizaria primeiro com Python? Deixe sua sugestão nos comentários!